Lägg till som läxa
Lägg till som stjärnmärkt
Frågor hjälpmarkerade!
Alla markeringar försvinner.
KURSER /
Matematik 1b
/ Statistik
Felkällor och felmarginal
När statistiska undersökningar görs är det viktigt att förstå vilka felkällor som kan finnas. Dvs orsaker till att undersökningens resultat inte blir bra. Här lär vi oss om dessa och vad felmarginal är.
Urvalsfel och svarsbortfall
Om vi inte tar hänsyn till ovanstående när vi gör urvalet riskerar vi att det inte blir representativt. Då kan det bli ett skevt urval, ett urvalsfel, vilket kan leda till ett missvisande resultat.
Vid en undersökning måste vi räkna med ett visst svarsbortfall. Det finns nämligen oftast ett antal efterfrågade svar som uteblir. Bortfall är alltid ett problem vid statistiska undersökningar. Det kan nämligen resultera i att urvalet inte längre är representativt för hela populationen. Därför är det viktigt att vi har koll på bortfallet när vi analyserar resultatet. Ju större bortfall undersökningen har, desto mer osäkert kan studiens resultat vara.
För att skapa en större tillförlitlighet gör vi därför bortfallsundersökningar och beräkningar av felmarginalen. Därefter räknar vi om resultatet för att få en mer sanningsenlig bild av verkligheten.
Felkällor
Ju fler individer eller enheter som deltar i undersökningen, ju bättre resultat. Vi måste alltså fråga tillräckligt många personer för att få en så liten felmarginal som möjligt i en opinionsmätning. Frågar vi för få finns det en risk för att resultatet inte är representativt för hela populationen. Bäst vore givetvis att undersöka hela populationen, men det finns det oftast inte resurser till.
Några av de felkällor vi bör tänka på vid analysen av undersökningen är svarsbortfallet, felaktigt ifyllda formulär, otydligt formulerade frågor och andra olika mätfel som bidrar till ett urvalsfel — alltså att undersökningens resultat i stickprovet inte motsvarar resultatet för hela populationen.
Felmarginal
Med hjälp av följande formel försöker vi säkerställa att en undersökning är tillförlitlig.
$f=1,96\cdot$ƒ =1,96· $\sqrt{\frac{p\left(100-p\right)}{n}}$√p(100−p)n där $n$n är stickprovets storlek och $p$p den procentuella andelen av populationen.
Felmarginalen $f$ƒ anges i procentenheter. Vi antar att det verkliga resultatet bör landa någonstans i intervallet resultatet plus minus felmarginalen, alltså $\pm f$±ƒ .
På grund av olika faktorer och slumpen händer det ändå att beräkningen av felmarginalen är fel. Men denna formel anses åtminstone ge korrekt svar i $95$95 av $100$100 fall. Ett så kallat $95\%$95%-igt konfidensintervall.
Konfidensintervallet = Uppmättvärde ± felmarginal
Om ett resultat av en undersökning landar i intervallet för felmarginalen anses undersökningen vara statistiskt säkerställd.
Exempel 2
Vid en undersökning svarade $10\%$10% av de tillfrågade att de tänkte köpa ett schampo som företaget gjorde reklam för. Felmarginalen på $95\%$95%-nivå beräknades till $2,3$2,3 procentenheter. Inom vilket intervall kan vi förvänta oss att schampot faktiskt kommer köpas av de tillfrågade?
Lösning
Det sanna värdet är i $95$95 av $100$100 fall att det är mellan $\left(10\pm2,3\right)\%$(10±2,3)%, alltså mellan $7,7\%$7,7% och $12,3\%$12,3% av de tillfrågade som kommer köpa schampot.
I fem fall av hundra är felmarginalen för liten och det sanna värdet ligger utanför intervallet.
Statistisk signifikans
Statistisk signifikans är ett mått på hur osannolikt det är att tillfälligheter gett de uppfattade sambanden. Genom olika mindre testgrupper kan vi värdera och vikta sannolikheten för att utfallen är slumpmässiga eller sanningsenliga och på så vis fastslå en statistisk signifikans.
Att räkna ut sådana sannolikheter, så kallade signifikansvärden, är lite klurigt och inget vi lär oss i denna kurs. Men det kan ändå vara bra att känna till vad det är.
Om olika konfidensintervall inte överlappar varandra säger vi att undersökningen är statistiskt säkerställd, eller statistiskt signifikant.
Exempel 3
Andelen elever som har med sig frukt till skolan har i en undersökning visat sig minska med tiden.
År $2000$2000 andel medhavd frukt $\left(64\pm5\right)\text{ }\%$(64±5) %
År $2010$2010 andel medhavd frukt $\left(53\pm5\right)\text{ }\%$(53±5) %
År $2020$2020 andel medhavd frukt $\left(49\pm5\right)\text{ }\%$(49±5) %
Är minskningen statistiskt signifikant mellan åren i undersökningen?
Lösning
Vi beräknar konfidensintervallen för åren.
Intervallet $2000$2000 var $59$59 till $69\text{ }\%$69 %
Intervallet $2010$2010 var $48$48 till $58\text{ }\%$58 %
Intervallet $2020$2020 var $44$44 till $54\text{ }\text{ }\%$54 %
Då vi ser att intervallen överlappar mellan $2010$2010 och $2020$2020 är den minskningen inte signifikant. Men mellan åren $2000$2000 och $2010$2010 överlappar inte intervallen, vilket ger en statistiskt signifikant (säkerställd) minskning.
Kommentarer
██████████████████████████
████████████████████████████████████████████████████
e-uppgifter (8)
-
1. Premium
$400$400 slumpmässigt utvalda elever fick frågan:
Äter du frukost varje dag?
Svaren som kom in fördelade sig på följande vis.
Ja : $210$210 elever
Nej : $120$120 elever
Hur stort bortfall hade undersökningen?
Rättar...2. Premium
Resultatet från tre olika statistiska undersökningar gav följande resultat.
Undersökning A: $\left(32\pm2\right)\text{ }\%$(32±2) %
Undersökning B: $\left(76\pm1\right)\text{ }\%$(76±1) %
Undersökning C: $\left(37\pm3\right)\text{ }\%$(37±3) %
Vilken undersökning hade störst felmarginal?
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: felmarginal statistikRättar...3. Premium
I en klubb har vi gjort en undersökning på medelvärdet av antal gjorda mål per säsong och fick resultatet $\left(54\pm6\right)$(54±6) mål.
Vilket konfidensintervall på $95\text{ }\%$95 %-nivå motsvarar medelvärdet för antal gjorda mål i klubben?
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: felmarginal statistikRättar...Din skolas prenumeration har gått ut!Din skolas prenumeration har gått ut!4. Premium
Andelen elever på Nordskolan som idrottar regelbundet på fritiden har i en undersökning visat sig minska med tiden.
År $2000$2000 andel idrottsutövande $\left(54\pm5\right)\text{ }\%$(54±5) %
År $2010$2010 andel idrottsutövande $\left(43\pm5\right)\text{ }\%$(43±5) %
År $2020$2020 andel idrottsutövande $\left(39\pm5\right)\text{ }\%$(39±5) %
Är minskningen statistiskt signifikant mellan åren $2010$2010 till $2020$2020?
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: signifikans statistik statistiskt säkerställdRättar...5. Premium
Vilket av följande alternativ nedan riskerar att ge ett missvisande resultat på grund av ett urvalsfel?
Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: bortfall felkällor urvallsfelRättar...6. Premium
En undersökning vill planlägga Svenskars matvanor. Undersökningen bygger på intervjuer enbart av personer forskaren känner.
Vilket av följande alternativ riskerar mer än de andra att ge ett missvisande resultat på grund av ett mätfel?
Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: bortfall felkällor urvallsfelRättar...7. Premium
En skola skickade ut en enkät med tio frågor kring skolmaten till elevernas föräldrar. Tyvärr var bortfallet i undersökningen $62\%$62%.
Hur kan man göra för att få ett säkrare resultat?
Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: bortfall bortfallsanalys statistik svarsbortfallRättar...8. Premium
I undersökningen ovan kring skolmaten svarade $45\%$45% av föräldrarna att man tyckte att det var en bra idé att ha efterrätt till eleverna på fredagar.
När man ringer upp ett stickprov ur bortfallet, det vill säga ett antal bland de $62\%$62% som inte svarade på enkäten, är det istället $75\%$75% som anser att det är en bra idé med efterrätt.
Ungefär hur stor andel av föräldrarna kan vi efter bortfallsundersökningen anta är positivt inställda till efterrätt?

Svara i hela procent.
Rättar...c-uppgifter (3)
-
9. Premium
En myndighet gör en rundringning till $4560$4560 slumpvis valda personer i Sverige och frågar dem om deras syn på skattensatsen i Sverige. Frågan gällde om man ansåg att skatten skulle höjas, sänkas eller var lagom som den var vid tillfället för undersökningen?

$35,6\%$35,6% av de tillfrågade svarade att de ville att skatten skulle sänkas.
Beräkna resultatets felmarginal med formeln
$f=1,96\cdot\sqrt{\frac{p\left(100-p\right)}{n}}$ƒ =1,96·√p(100−p)n
där p = procentuell andel och n= stickprovsstorleken
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: felmarginalRättar...10. Premium
Felmarginalen beskriver i vilket intervall resultatet för en hel population befinner sig när man gjort en stickprovsundersökning. Så kallat konfidensintervall. Detta är vanligt vid opinionsundersökningar inför val. Vid en sådan undersökning fick man följande resultat
Parti A: $15,3\%$15,3% med felmarginalen $\pm1,3$±1,3
Parti B: $16,8\%$16,8% och en felmarginal på $\pm1,4$±1,4
Jonas säger att det med säkerhet kommer gå bättre för parti B men Anna säger emot. Resonera kring hur de båda kan ha tänkt.
Svar:Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: felmarginal statistikRättar...11. Premium
I april 2003 röstade medborgarna i Ungern om medlemskap i EU. Vid sammanräkningen av rösterna visade det sig att $84$84 % röstade Ja till medlemskap i EU
samt att $45$45 % av de röstberättigade deltog i valet.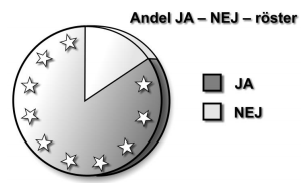
Undersök mellan vilka procenttal andelen Ja-röster skulle kunna ligga om samtliga röstberättigade hade deltagit i valet.
Avrunda till hela procent.
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: spridningsmått statistik variationsbreddRättar...a-uppgifter (2)
-
12. Premium
En idrottsförening har $500$500 medlemmar. Styrelsen planerar att låta bygga en klubbstuga. Eftersom frågan är så viktig för klubben tänker styrelsen bygga stugan endast om en majoritet av föreningens samtliga medlemmar kan förväntas stödja planerna.
Man ordnade därför ett medlemsmöte. Tyvärr kom bara $185$185 medlemmar. Av dessa ville $125$125 att stugan skulle byggas och de övriga att den inte skulle byggas.
Eftersom så många medlemmar inte deltog i mötet gjorde styrelsen en kompletterande undersökning. De ringde till $75$75 slumpvis utvalda medlemmar som ej var närvarande vid mötet. Av dessa svarade $26$26 Ja och $49$49 Nej.
Tycker vi att styrelsen bör besluta sig för att bygga stugan?
Ta hänsyn till resultaten från både medlemsmötet och den kompletterande undersökningen.Ange svaret Ja eller Nej, men träna även på att motivera ert svar.
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: bortfall bortfallsundersökning statistik statistisk undersökning svarsbortfallRättar...13. Premium
Vid ett obundet slumpmässigt stickprov var felmarginalen $3\%$3% på konfidensnivån $95\%$95%. Den procentuella andelen var $60\%$60%. Hur stort var stickprovet?
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: felmarginalRättar... -
Din skolas prenumeration har gått ut!Din skolas prenumeration har gått ut! -
Redigera uppgift Stäng Kopiera abc-fråga Flytta abc-fråga Länka abc-fråga Uppgiften är en del av en abc-fråga. Vad vill du göra?
Lägg till uppgift Det finns inga befintliga prov.
-
{[{ test.title }]}
●
Namnet måste vara 4-60 tecken långt. Rapportera fel Lektion
{[{lessonData.title}]}
Kategori
{[{reportType}]}
ID
{[{reportId}]}
Beskriv med minst 10 tecken. Byt kurs Test i 7 dagar för 9 kr.
Det finns många olika varianter av Lorem Ipsum, men majoriteten av dessa har ändrats på någotvis. Antingen med inslag av humor, eller med inlägg av ord som knappast ser trovärdiga ut.
Köp Premium Avbryt Din skolas prenumeration har gått ut!Övningsuppgifter ej tillgängliga!Stäng Din skolas prenumeration har gått ut!Exempel i videon. 
Logga in
viaeller medGör om alla uppgifter All svar raderas. Detta går inte att ångra detta.
Radera Avbryt Genom att använda den här sidan godkänner du våra användarvillkor, vår integritetspolicy och att vi använder cookies.
Endast Premium-användare kan kommentera.