Lägg till som läxa
Lägg till som stjärnmärkt
Frågor hjälpmarkerade!
Alla markeringar försvinner.
KURSER /
Matematik 2b
/ Statistik
Repetition Statistik
Innehåll
I den här lektionen får du en repetition av statistik. Vi repeterar begreppen median, medelvärde, variationsbredd och typvärde. Återvänd till respektive lektion om du känner dig osäker och fördjupa sedan din förståelse i lektionen lägesmått och spridningsmått.
Statistik inom matematik
Statistik kallas den del inom matematiken som sammanställer, tolkar och analyserar information om något. Det kan vara analys av människor, djur, naturs beteende eller egenskaper, om ekonomi eller egentligen vad som helst. Med statistiska beräkningar försöker man hitta mönster, logik, samband och kunna göra slutledningar om t.ex. människors åsikter, tankar eller värderingar.
Under historiens gång har matematiker förfinat denna gren inom matematiken och utvecklat metoder som ger analyserna större och större samstämmighet med verkligheten och olika skeenden.
Grundbegrepp inom statistiken
I lektionen går vi igenom de grundbegrepp du behöver kunna för att själv göra sådana undersökningar. Gå till respektive lektion för att repetera enskilda begrepp eller få en fördjupning. Viktiga grundbegrepp att kunna är följande.
Statistik
Den gren inom matematiken som sysslar med insamling, utvärdering, analys och presentation av data eller information kallas statistik.
Datamängd
Alla de olika resultat och/eller mätvärden man får in vid en undersökning kallas för datamängden.
Observation
De resultat och/eller iakttagelser man gör i samband med en undersökning kallas för observationer. Observationerna delas sedan in i olika observationsvärden för att lättare sortera och kategorisera de olika observationerna.
Frekvens
Antalet gånger varje observationsvärde förekommer kallas för observationens frekvens.
Relativ frekvens
Frekvensen angiven som en andel, oftast i procent, kallas relativ frekvens.
Lägesmått
Lägesmått är värden som sammanfattar alla mätvärden i en datamängd med ett enda representativt värde.
Spridningsmått
Spridningsmått anger hur observationerna i datamängden varierar kring lägesmåttens värden.
Medelvärde
Medelvärdet anger datamängdens genomsnittliga värde.
$\text{Medelvärde}=$Medelvärde= $\frac{\text{Summan av alla värden}}{\text{Antal värden}}$Summan av alla värdenAntal värden
Median
Medianen anger mittenvärdet i datamängden när den står i storleksordning. Vid jämnt antal värden blir medianvärdet medelvärdet av de två mittersta värdena.
Typvärde
Typvärdet motsvarar det vanligast förekommande värdet i en datamängd. Alltså det värde med högst frekvens.
Variationsbredd
Variationsbredden är ett spridningsmått som anger skillnaden mellan det största och det minsta värdet.
Som vi tidigare nämnt presenteras spridningsmått och lägesmått ofta tillsammans för att beskriva en undersökningsresultat så bra som möjligt.
Exempel 1
Två personer kastar dart. Nedan följer deras poäng för fyra kast var.
Poäng person 1
${ 10, 10, 10, 10 }$
Poäng person 2
${ 0, 0, 0, 40 }$
För vem gick det bäst?
Lösning
Båda personerna fick totalpoängen $40$40 och medelvärdet $10$10 poäng. Men det är ganska stor skillnad mellan de två personernas resultat.
Person 1 är antalet poäng väldigt samlat kring medelvärdet. Eller rättare sagt, inget värde avviker alls från medelvärdet $10$10. Alla värden är till och med lika med medelvärdet.
Däremot avviker alla värdena ganska mycket från medelvärdet $10$10 poäng för person 2. Därmed har person 2 en större spridning.
Sammanfattningsvis har personerna olika spridning, även om medelvärdet är detsamma. Men för vem det gick bäst? Ja, det beror nog på vem du frågar!
De olika måtten visar alltså olika saker. Därför är det viktigt att tänka efter en extra gång hur representativt eller rättvisande ett mått verkligen är i förhållande till datamängden.
I lektionen lägesmått och spridningsmått går vi igenom fler exempel på hur man genomför beräkningar på de olika värdena.
Olika diagram
Beroende på vilken datamängd du vill presentera lämpas sig olika diagram olika bra. Här repeterar vi nu några av de diagram vi gick igenom mer ingående i lektionen Diagram och tabeller.
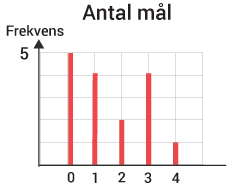
Stolpdiagram
Ett stolpdiagram lämpar sig väl då observationerna motsvarar vissa värden, ofta numeriska heltalsvärden.
Cirkeldiagram
Om man har ett litet antal olika observationer kan cirkeldiagrammet vara ett bra sätt att redovisa sin data.
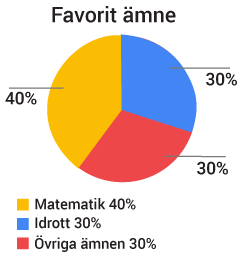
De olika sektorerna i cirkeln motsvarar tillsammans $100\%$100% av datamängden. Vinkeln för varje sektor beräknas genom att multiplicera andelen i decimalform med $360^{\circ}$360∘.
Histogram
I lektionen lägesmått och spridningsmått presenterar vi ett nytt diagram som kallas för histogram.
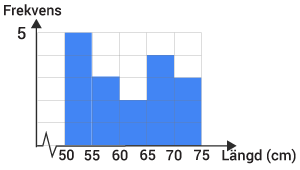
I histogrammet delar man in datamängden i olika intervall, så kallade klasser, för att få ett mer överskådligt diagram om datamängden är väldigt utspridd.
Lådagram
Lådagram är ett diagram som visar spridningsmått på ett tydligt vis och är nytt för kursen. I lektionen lådagram går vi ingående igenom hur man läser av och konstruerar ett lådagram, men redan nu får ni ett exempel på hur de kan se ut nedan.
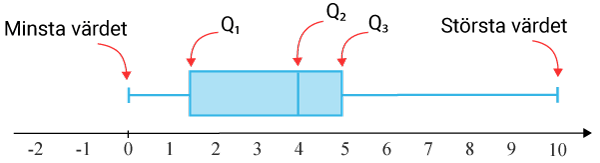
Nya lägesmått och spridningsmått
Spridningsmått och lägesmått presenteras ofta tillsammans för att beskriva en undersökningsresultat så bra som möjligt.
I högstadiets kurser och Matematik 1 gick vi ingående igenom lägesmåtten medelvärde, median och typvärde. Där diskuterade vi även att de olika lägesmåtten passar bra att använda i olika situationer. Genom att känna till hur datamängdens observationer är fördelade kan man lättare avgöra vilket lägesmått som lämpar sig bäst.
I denna kurs kommer vi att fördjupa lägesmåtten genom att jobba med material som är normalfördelade. Det innebär att de fördelas sig på ett särskilt vis kring medelvärdet enligt en kurva som även finns på formelbladet för kursen.
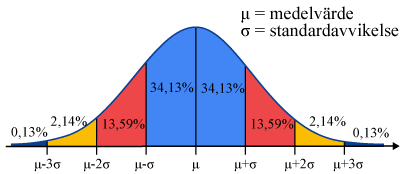
Är datamängden någorlunda normalfördelad är medelvärdet ett bra lägesmått. Däremot kan medianen eller typvärdet vara ett mer rättvisande lägesmått om materialet är snedfördelat. Med andra ord får man vara observant på vilket mått som ger det tydligaste och mest sanningsenliga informationen. Sammanfattningsvis gäller att för olika datamängder är de tre lägesmåtten olika missvisande.
Återvänd till lektionen medelvärde, median och typvärde, samt lägesmått och spridningsmått om du känner att du behöver repetera mer.
I en datamängd där observationerna har en liten spridning är de flesta värden nära varandra. Däremot säger man om en datamängd där värdena skiljer sig mycket från varandra, att spridningen är stor.
Vi har redan bekantat oss med spridningsmåttet variationsbredd.
I kommande lektioner kommer vi även introducera spridningsmåtten standardavvikelse, varians och percentilavstånd.
Korrelation och kausalitet
Ibland finns samband mellan två olika datamängder. Då kan man göra en så kallad två-variabelanalys. Här är två centrala begrepp att repetera.
Korrelation betyder att två olika variabler följs åt på ett tydligt sätt. Hittills har vi fokuserat på linjär korrelation.
Positiv linjära korrelation gäller när två olika variabler följs åt på viset att när den ena ökar, ökar även den andra. Vid negativ korrelation minskar när den första variabeln ökar.
Korrelationen kan vara olika stark, vilket blir tydligast om man ritar ett spridningsdiagram och iakttar hur samlade de olika punkterna är längs en linje eller en annan typ av funktion. När det finns en tydlig korrelation kan man anpassa modeller som beskriver denna korrelation. Det kallas regression eller funktionsanpassning. I lektionerna Regressionsanalys med Geogebra och Regressionsanalys med Grafräknare i tittar vi närmare på hur man kan göra regressionen med hjälp av digitala verktyg.
Kausalitet beskriver om det finns ett orsakssamband mellan två variabler.
Även om det finns en korrelation mellan variablerna som motsvarar punkterna i spridningsdiagrammet, så är det inte säkert att det finns ett orsakssamband, eller med andra ord råder kausalitet, mellan variablerna. Det kan vara slumpen som gör att det ser ut att finnas ett samband även om det egentligen inte gör det. Två händelser där man sett en korrelation mellan mätvärdena kan till exempel bero på en tredje händelse. Men om kausalitet råder mellan två fenomen, kallas det ena orsak och det andra verkan.
Kommentarer
██████████████████████████
████████████████████████████████████████████████████
e-uppgifter (5)
-
1. Premium
Diagrammen nedan visar åldersfördelningen på tre olika arbetsplatser.
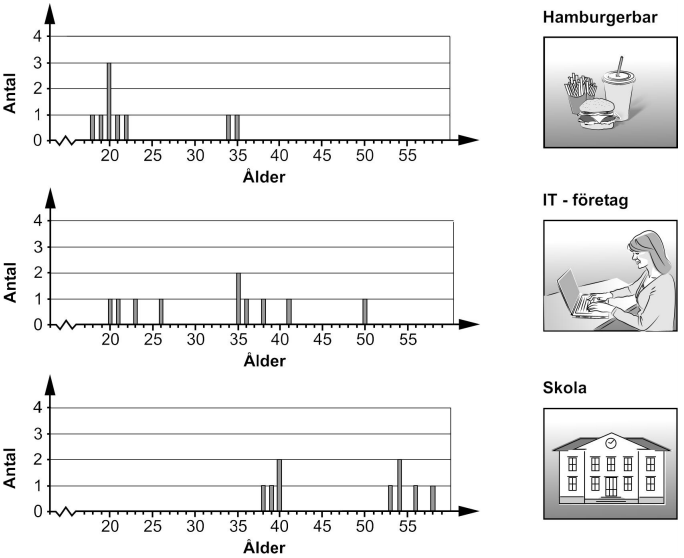
Hur stor är den största variationsbredden på åldern?
Endast svar fordras.Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Se mer:Videolektion: Lägesmått och spridningsmåttLiknande uppgifter: spridningsmått statistik variationsbreddRättar...2. Premium
Stapeldiagrammet visar hur många poäng de olika deltagarna fick vid en tävling.
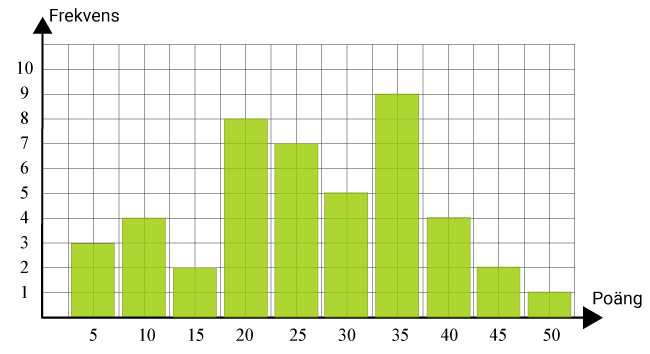
a) Vilket är typvärdet?
b) Hur många deltagare hade tävlingen?
Svar:Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Se mer:Videolektion: Lägesmått och spridningsmåttLiknande uppgifter: frekvens Lägesmått och Spridningsmått stapeldiagram statistik typvärdeRättar...3. Premium
Är medelvärdet, medianen eller typvärdet störst i undersökningen som presenteras i stapeldiagrammet nedan?
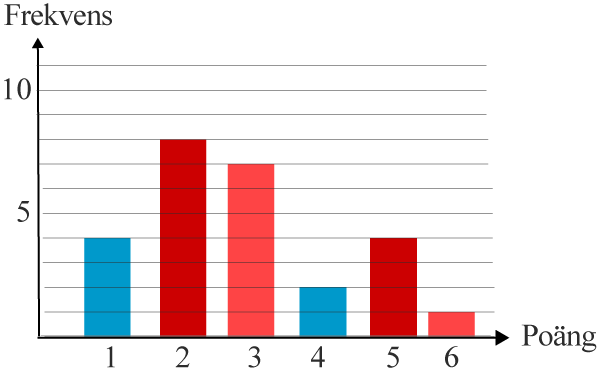 Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: Diagram Lägesmått och Spridningsmått medelvärde median Sannolikhetslära och Statistik statistik typvärdeRättar...Din skolas prenumeration har gått ut!Din skolas prenumeration har gått ut!4. Premium
Vilket diagram förknippar du mest med begreppet svag korrelation?
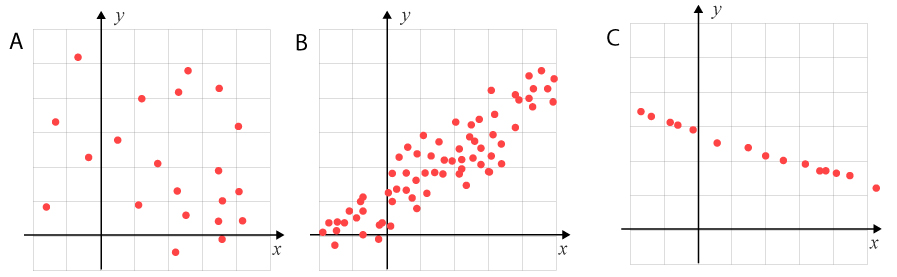 Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: Matematik 2 Prov statistik typvärdeRättar...5. Premium
Välj det påstående nedan som stämmer.
Det finns en positiv korrelation mellan…
Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: korrelation statistikRättar...c-uppgifter (4)
-
6. Premium
Jonna väljer att göra en beräkning i kalkylprogrammet i ruta E5. Vad är det hon beräknar och hur mycket blir det?
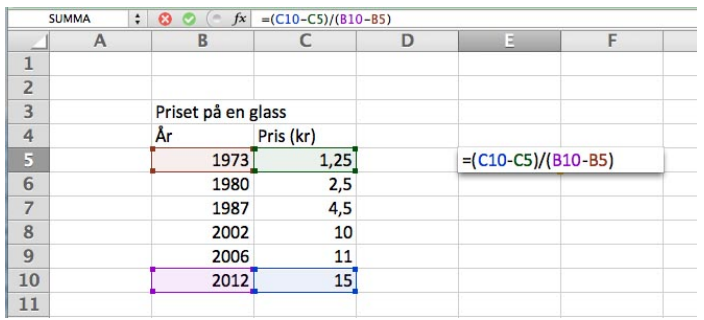 Bedömningsanvisningar/Manuell rättning
Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: genomsnittlig förändring kalkylprogram nationella provRättar... -
7. Premium
Gör ett spridningsdiagram över tabellen och avgör om det finns någon korrelation mellan $x$x och $y$y värdena.
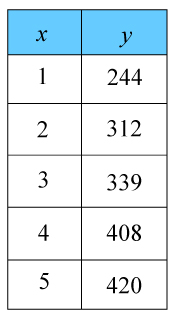
Ange endast svaret Ja eller Nej.
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: funktionsanpassning korrelation linjär regression statisitkRättar...8. Premium
Medianen för tre heltal är $34$34. Medelvärdet är $26$26 och variationsbredden $30$30.
Vilka är de tre talen?
Svar:Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Se mer:Videolektion: Repetition Statistik Median, Medelvärde och TypvärdeLiknande uppgifter: Algebra begrepp medelvärde median statistik variationsbreddRättar...9. Premium
I tabellen nedan visas lönerna för en antal anställda på ett företag.

Vilket av lägesmåtten median, medelvärde eller typvärde är mest lämpligt att använda för att beskriva de anställdas lönenivå?
Beräkna lägesmåtten och motivera sedan vilket av dem som är bäst.
Svar:π²Ditt svar:Rätt svar:(Korrekta varianter)Ger rätt svar {[{correctAnswer}]}Bedömningsanvisningar/Manuell rättningRätta själv Klicka i rutorna och bedöm ditt svar.-
-
Rättad
-
+1
-
Rättad
Liknande uppgifter: lägesmått medelvärde median statistik typvärdeRättar... -
Din skolas prenumeration har gått ut!Din skolas prenumeration har gått ut! -
Det finns inga befintliga prov.
-
{[{ test.title }]}
●
Lektion
Kategori
ID
Test i 7 dagar för 9 kr.
Det finns många olika varianter av Lorem Ipsum, men majoriteten av dessa har ändrats på någotvis. Antingen med inslag av humor, eller med inlägg av ord som knappast ser trovärdiga ut.

Logga in
viaAll svar raderas. Detta går inte att ångra detta.
Jenny Arvidsson
Hej! I uppgift 6 står det att medianen är mest lämplig att använda, eftersom den är 24500. Men 2800 står i mitten och är väl medianen? Och då undrar jag om den är lämplig att använda för att beskriva lönenivån.
Anna Eddler Redaktör (Moderator)
Hej Jenny,
när du kollar medianen måste du ta hänsyn till frekvensen. Som du ser finns det många fler som har 22 000 och 24 500 i lön är högre alternativ. Så medianen är inte det mittersta värdet av de i tabellen utan av alla löner med hänsyn till frekvensen.
Hoppas det blev tydligt.
Yaiya Siekas
Men snälla Simon Rybrand och Anna Admin, vi är tre stycken som säger att största värdet är 8 och inte 6 eller 5. Alltså måste variationsbredden vara 8 – 1 = 7? Eller har jag blivit helt galen?
Anna Admin (Moderator)
Hej Yaiya.
Se gärna min kommentar till Per-Olov. Hoppas den kan förtydliga hur vi räknat.
Erik Olsson
På första frågan är inte största värdet 6.
Anna Admin (Moderator)
Hej.
Vi söker inte största värdet utan variationsbredden. Den får du genom att ta största värden minus minsta värdet, vilket i detta fall är $6-1=5$
Per-Olov Sundman
Fråga nummer 1: Största värde i stapeldiagrammet är 8 så variationsbredden = 8-1 = 7. Inte 6-1 = 5 som står som ”rätt svar”.
Anna Admin (Moderator)
Hej Per-Olov,
När man talar om ”största värdet” så syftas det i detta fallet på poängen, inte frekvensen. Alltså inte hur många som fått ett enskilt värde, i detta fall olika poängsummor, utan vilka värden, poängsummor. Vi är alltså intresserad av variationsbredden på poängen. Det högsta poängen i uppgiften är $6$ poäng och det minsta $1$. Där av variationsbredden $6-1=5$.
Skulle vi söka variationsbredden på frekvensen, vilket är mer ovanligt, så skulle vi fått $8-1=7$. Men så var inte fallet här.
Nebosja Kostic Hermods Gymnasium STHL
I uppgift 1. Bestäm variationsbredden på datamängden som redovisas i stapeldiagrammet.
är variationsbredden 8-1=7 och inte 6-1=5 som ni föreslår i facit
Simon Rybrand (Moderator)
Hej
Nej, det stämmer med $6-1=5$, då det är variationsbredden på poängen som avses.
Yaiya Siekas
VA? Största värdet är ju 8 och minsta värdet är 1. Då är väl ändå variationsbredden 7? Annars förstår jag inte
John Parman
Hur räknar man typvärde om det inte finns något exakt likadant förekommande värde såsom : 20, 40, 50, 60, 100 tex
Simon Rybrand (Moderator)
Man kanske kan säga att typvärde är ett irrelevant mätvärde med en sådan utfallsmängd. Har du en uppgift på just detta eller är det mer en fundering?
B.E
Hej igen! Äsch förlåt, jag glömde att lista värdena från minsta till högsta. Då blir det ju mycket riktigt 14, inte 20. Sorry!
Simon Rybrand (Moderator)
Ingen fara! Fortsatt lycka till med statistiken!
B.E
Hej!
Jag har gjort uppgift 2 i statistikdelen. Ni skriver att medianen blir 14, men det kan ju inte stämma om man räknar. Jag får det till 20, har jag fel och hur tänker ni i så fall? / Boel
Perihan Yildiz Göker
har ni inga mer statistik videos?
Simon Rybrand (Moderator)
Hej, jodå det har vi, gå till Matematik 2 och kika under kapitlet Statistik så hittar du mer.
petroffaw
Hej! En fråga om medianvärde på en udda serie som i fråga 2, varför väljs 20 och inte 14?
Med vänliga hälsningar Petra Wikström
Simon Rybrand (Moderator)
Hej Petra, för att kunna hitta medianvärdet krävs att man ordnar talen i ordningsföljd först. Så när detta är gjort så blir mittentalet (medianen) 14.
Sinisa
32 år som medelåldern när de lämnar första våningen 🙂
Sackeus
Hur ser den uträkning ut, som du använder för att komma fram till det?
Victor Hartman
(a+b+c+d+e)/5 = 30 år
a+b+c+d+e = 30 * 5 = 150
a+b+c+d+X = 150 + 10 = 160
(a+b+c+d+X)/5 = 160/5 = 32 år
ilyaas cabdi
hej!! på den sista fråga gjorde jag så här x+1+4-x+4=9 –> x= 4 Men ni säger x=10 hur? om man lägger ihop alla tre åldrar ” Bo,lasse och Lisa” det ska blir 9 det fattar jag.
men 3x – 3 / 3 det fattar jag inte, vrf ska man dividera med 3? hur fick ni fram 3x-3
plus när jag la hopp alla tre då STÄMDE VL=HL x=10 ”Lasse” Z=x+1 –> 11 ”Bo” och ”Lisa” y=4-10=-6 11 + (-6) + 10 inte lika med 9
ville komma fram till om lägger ihop x+z+y = 9 VL och Hl är inte lika
Anna Admin (Moderator)
Hej Ilyaas.
Det är inte summan av alla åldrarna som är nio, utan medelvärdet av syskonens åldrar. Vi beräknar medelvärden genom att beräkna kvoten mellan summan av alla värden dividerat med antal värden.
Alltså $\text{Syskonens medelålder}=\frac{\text{Summan av syskonens åldrar}}{\text{Antalet syskon}}$
Om Lasse är $x$ år, blir summan av syskonens ålder $x+(x+1)+(x-4)=3x-3$ år, eftersom att Bo är ett år äldre än Lasse (x+1) och Lisa fyra år yngre (x-4). Nu kan vi med hjälp av ekvationen $9=\frac{3x-3}{3}$ bestämma $x$.
Hoppas detta gick att förstå. Hör av dig igen annars.
Lycka till med ekvationerna!
mitchtimmy
Hej, har ett exempel med medelvärde som jag tycker är svårt
I en hiss som startar från bottenvåningen är medelåldern på personerna i hissen 30 år. Vid nästa stopp, på första våningen, kliver en person ur hissen och en person kliver på. Vad är medelåldern på personerna i hissen när den lämnar första våningen?
(1) Den som kliver på hissen vid första våningen är 10 år äldre än den som kliver ur.
(2) Det är fem personer i hissen när den startar från bottenvåningen.
Miguel
Gjorde ett tal i boken häromdagen och undrat över den sen dess.
Om två tärningar kastas. Vilken händelse har störst sannolikhet att poängsumman blir 5 eller att poängsumman blir 10?
Borde det inte vara svaret vara 10?
Simon Rybrand (Moderator)
Hej, det finns fler alternativ som ger summan 5 än summan 10 så det är störst sannolikhet att få summan 5.
Summan 5 ges av kombinationerna:
(1,4), (2,3), (3,2), (4,1) total 4 st.
Summan 10 ges av kombinationerna:
(4,6), (5,5), (6,4) total 3 st.
Harryhult
Medianen: Man tar dom två talen i mitten, adderar dom och delar på två.
Om det är ett jämnt antal tal.
Simon Rybrand (Moderator)
Hej och tack för din kommentar
Precis så fungerar det. Det kan vara viktigt att känna till att medianen beräknas lite olika för olika antal värden i den data man har samlat in vid en undersökning.
Ojämnt antal värden: Mittentalet är medianen.
Jämnt antal värden: Medianen är medelvärdet av de två mittersta talen.
Endast Premium-användare kan kommentera.